Statements Best Describes a Web Crawler
Each crawler thread removes the next URL in the queue. Each crawler thread fetches a document from the Web.
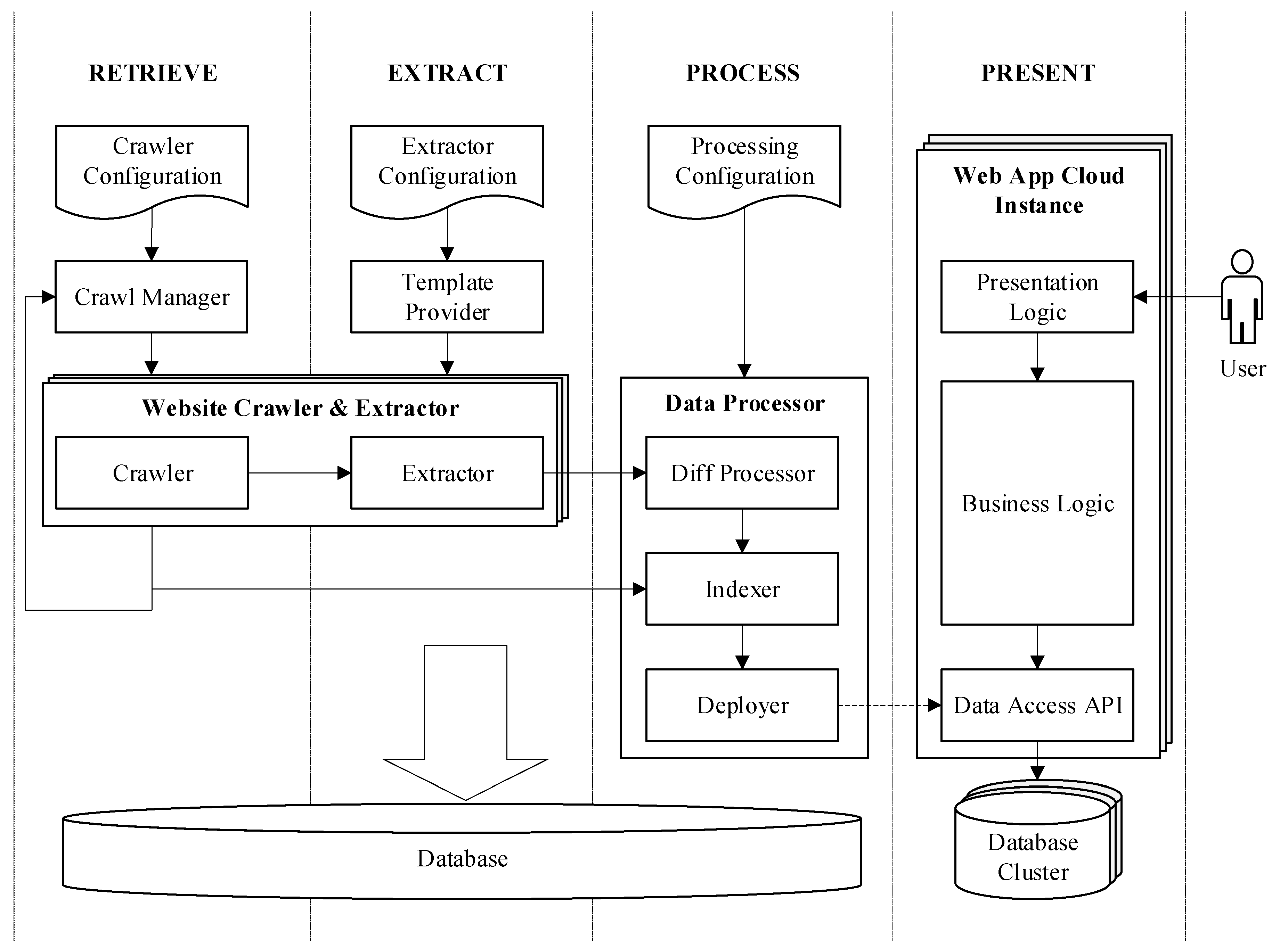
Information Free Full Text Optimization And Security In Information Retrieval Extraction Processing And Presentation On A Cloud Platform Html
The crawler caches the HTML file in the local file system.

. Part 2 - Creating a web crawler - we will describe how you can create a fully functional web crawler. It redirects Web pages to different sites if the link fails. As the name suggests the web crawler is a computer program or automated script that crawls through the World Wide Web in a predefined and methodical manner to collect data.
Identify a true statement about the function of Googles Ad Words. 21 Chronology Web crawlers are almost as old as the web itself. Also offers white pages and yellow pages.
A Web crawler an indexer a database and a query processor are all components of this. As an automated program or script web crawler systematically crawls through web pages in order to work out the index of the data that it sets out to extract. Titles images keywords other linked pages etc.
You might wonder what a web crawling application or web crawler is and how it might work. Origin of the question is Problem Solving topic in section Problem Solving of Artificial Intelligence. Or to check if a URL already.
Web Crawler is aan ____________. You have to create a memory size calculator in the. Web 10 communication tools are primarily.
This section first presents a chronology of web crawler development and then describes the general architecture and key design points of modern scalable crawlers. A Web crawler sometimes called a spider or spiderbot and often shortened to crawler is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing web spidering. The crawler thread scans the HTML file for hypertext links and inserts new links into the URL queue.
Features that web crawlers must provide followed by features they should provide. It presents a view of long-term technology integration. When the document is not in HTML format the crawler converts the document into HTML before caching.
There are multiple services for submitting your page to these search engines. An attack by an authorized user. The page is usually an HTML file containing text and hypertext links.
The crawler initiates multiple crawling threads. Web crawlers are metaphorically spiders - they need to have a way to traverse the web hyperlinks and arrive at your page. The purpose of spyware is to ______.
Duplicate links already in the document table are discarded. The evolution of the Internet from Web 10 to Web 20 platforms is the primary driver of the. It provides immediate communication to and receives feedback from customers.
We list the desiderata for web crawlers in two categories. Select the correct answer from above options. D Model based agent.
Documents you can in turn reach from links in documents at depth 1 would be at depth 2. My experience says that a web crawler has many parts and services and each part need some specific features. Which of the following statements best describes the view most companies hold about their employees engaging in.
To get your hypothetical page into a search engines results you must manually submit its URL to the search engine. Capture the users account data passwords key strokes and more. In the spring of 1993 shortly after the launch of NCSA Mosaic Matthew Gray implemented the World Wide Web Wanderer.
The web crawler tool pulls together details about each page. In terms of the process it is called web crawling or spidering. Chapter 8 - Strings - we will describe what strings are.
It presents a view of short-term technology integration. Documents you can reach by using links in the root are at depth 1. Web search engines and some other websites use Web crawling or spidering software to update their web content or indices.
Web Crawler is a bot that downloads the content from the internet and indexes it. Depending on your crawler this might apply to only documents in the same sitedomain usual or documents hosted elsewhere. To speed up the crawling process our web crawler will be developed as a multi-threaded program.
The Web contains servers that createspidertraps which aregen-erators of web pages that mislead crawlers into getting stuck fetching an infinite number of pages in a particular domain. The document is usually an HTML file containing text and hypertext links. From the following list select all the examples of internal threats to cybersecurity.
A Intelligent goal-based agent. By applying the search algorithms to the data collected by the web crawlers search engines can provide the relevant links as the response. A web sites root is at depth 0.
For example to cache web pages we need some thing like FILESTREAM of sql server. The crawler thread fetches the document from the Web. A search engine optimization marketer who plays by the rules of the system striving to provide good quality content with the best use of keywords and tags and earned links at reputable sites would be classified by social media insiders as a _____.
The main purpose of this bot is to learn about the different web pages on the internet. White hat web crawler black hat golden triangle gray hat. I got this question in my homework.
C Simple reflex agent. InfoSpace product offering combined results from Google Yahoo Bing and Ask. This kind of bots is mostly operated by search engines.
Web crawler function that starts with a URL install all the required repositories question_answer Q. You will also learn some useful string functions and how to escape characters in Python. Identify the term below that best describes a firewall feature that allows established related traffic through without making the firewall go through all of the rules again to find a match.
Searches the Web or only images video and news. The web crawler is an example of Intelligent agents which is responsible for collecting resources from the Web such as HTML documents images text files etc. Crawlers must be de.
Pdf Design And Implementation Of Scalable Fully Distributed Web Crawler For A Web Search Engine
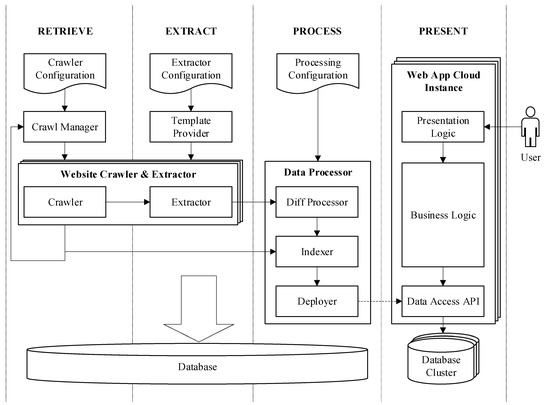
Information Free Full Text Optimization And Security In Information Retrieval Extraction Processing And Presentation On A Cloud Platform Html
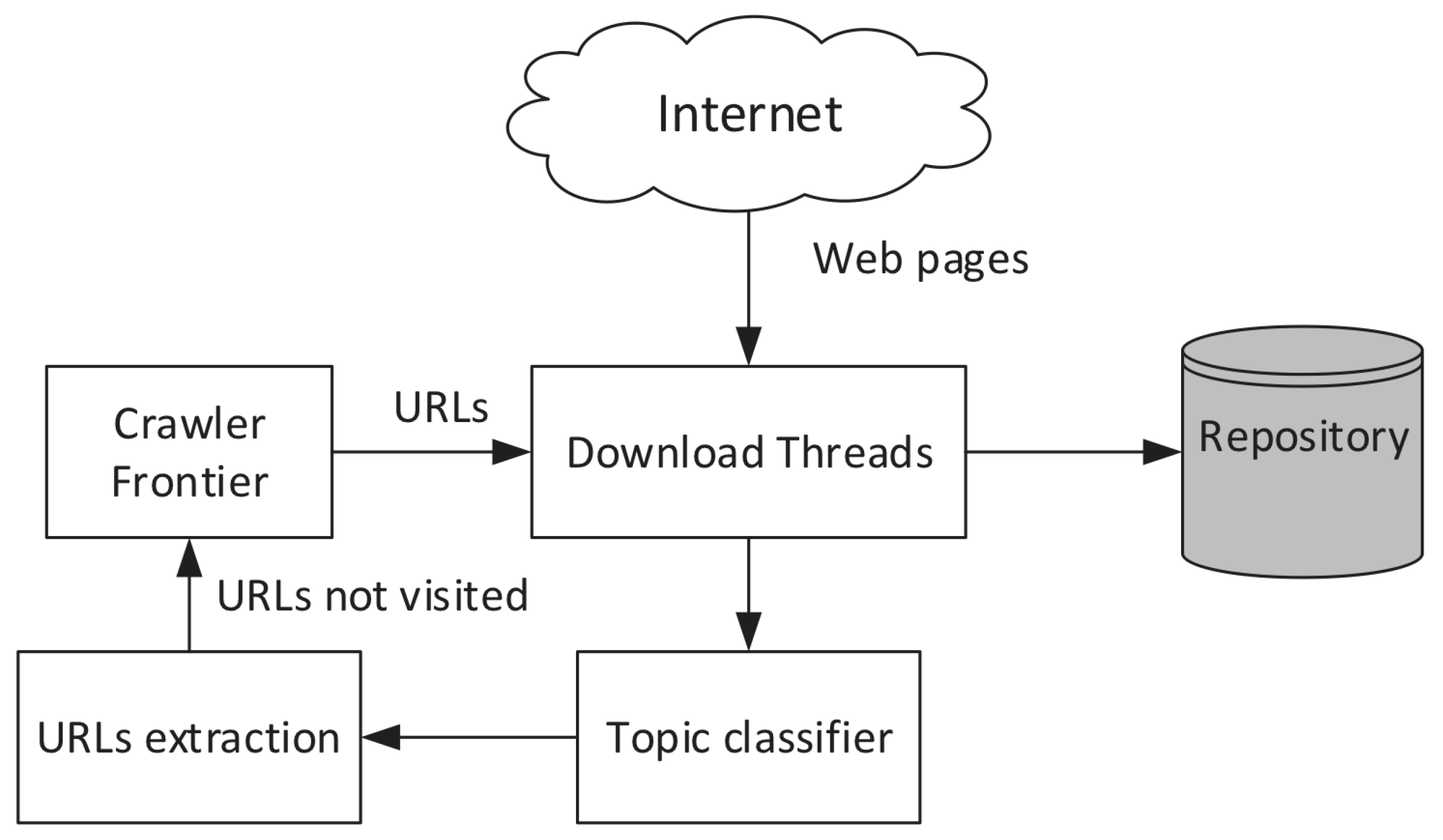
Applied Sciences Free Full Text A Semantic Focused Web Crawler Based On A Knowledge Representation Schema Html



Comments
Post a Comment